OUTDATED ARTICLE: This article has been superseded by a newer one. Please refer to that article instead.
Have you ever had to deal with the situation where your CI lags further and further as the day progresses because more builds are getting queued up for your long-running tests? Some of you may have tried to solve that by firing up multiple test environments and then assigning different builds to these different environments thereby achieving some parallelism but this can get very costly. Some of you may have tried converting your long-running tests into nightly jobs but this means you won’t get timely reports on broken builds.
So what’s a humble build engineer to do? Luckily, this problem has been solved by those before us. Specifically, I’m going to take a lesson from my CI/CD bible: Continuos Delivery by Jez Humble and David Farley.
To understand the strategy discussed in that book, a diagram is in order. Behold my mad diagramming skillz!!!111
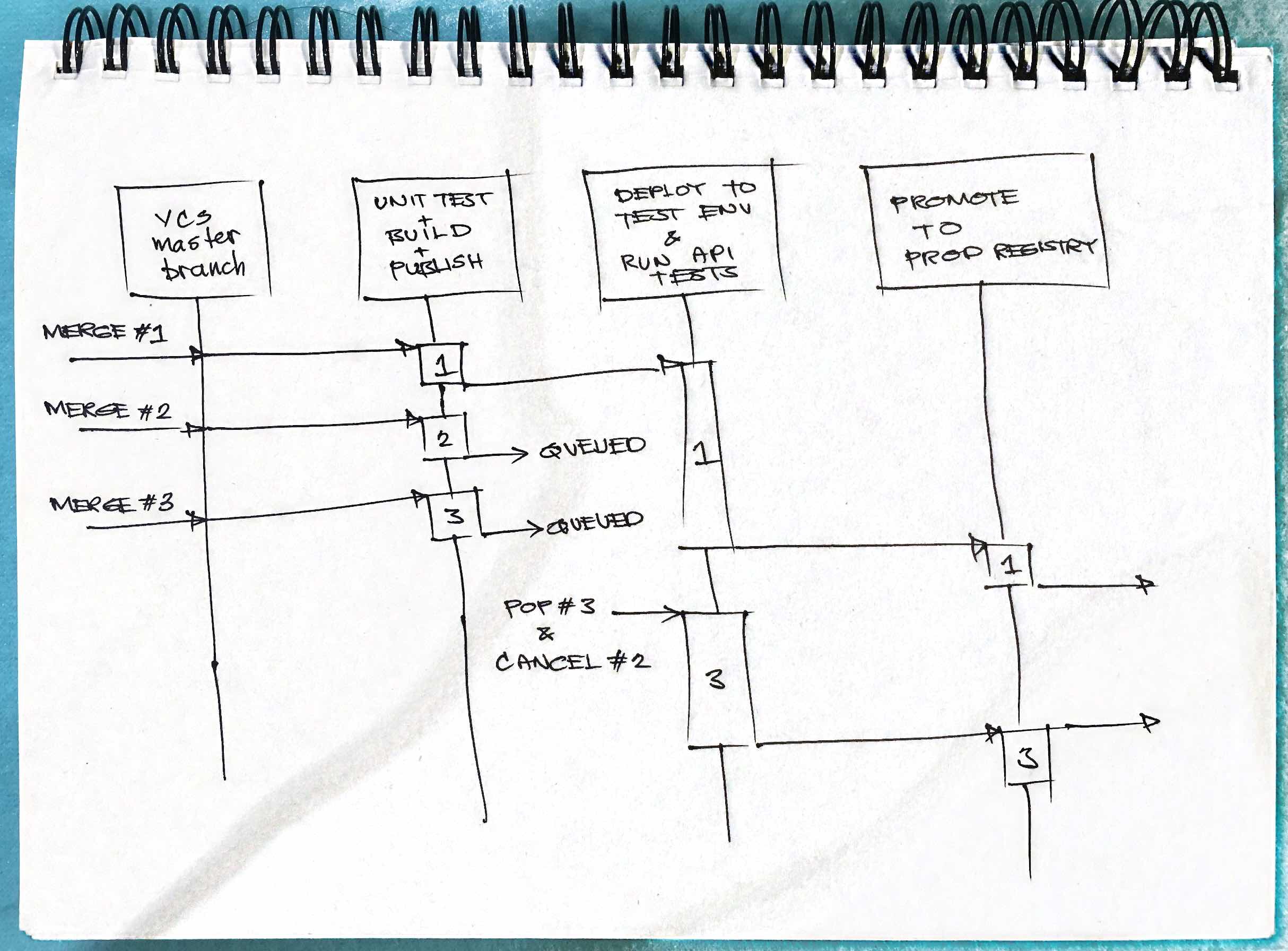
Before we get to the meat of that diagram, I want to bring your attention to the 3rd entity there. The one named “Deploy to Test Env and Run API Tests.” This kind of step in your CI/CD pipeline tends to be the one that sticks out like a sore thumb. It’s slow and lags as the day progresses. You’ll see its slowness represented in the diagram by the relatively long activation of build 1.
So let’s get to the details of the sequence diagram:
- Changeset #1 is merged to master
- This triggers build #1 which starts with the “Unit Test + Build + Publish” stage
- After build #1 is published to the registry, it then triggers the “Deploy + Run API Tests” stage which takes a while to complete as mentioned earlier.
- While build #1 has the “Deploy + Run API Tests” stage occuppied, builds #2 and #3 are published. Because #1 is still running, #2 and #3 are put in a LIFO queue.
- As soon as build #1 is done, the pipeline then pops from the LIFO queue which yields build #3. The pipeline then cancels everything left in the queue that’s older than #3 which, in this case, is build #2.
Discussion
By skipping one or more older builds in the queue, you achieve true continuous integration without sacrificing code quality since, even though build #2 was skipped, its changes (code + test) are alredy incorporated into build #3. Thus if build #3 passes, it’s safe to assume that changes that were part of build #2 are also passing.
There might also be a concern that build #2 might reduce overall code quality (e.g. reduced code coverage). Let’s assume that the build stage includes some static analysis tool execution. In such a case, if build #2 reduced code quality below tolerable levels, then it would fail on the build stage and never get queued for the API tests stage at all. This then signals the team to fix the problem.
Now there might be a case where builds W, X, Y, and Z are queued and when the API stage is ready, Z is popped and the other three cancelled. Let’s pretend that in this scenario, build Z failed the API tests. In such a case, how do we determine if the breaking change was introduced in build W, X, Y, or Z? If we want to get fancy with it, we could introduce some binary search procedure to determine where the build started breaking. That may work for certain teams but it may be too much trouble than it’s worth for some. One solution is to just look at the damn error and fix it in the next build!
One thing that hasn’t been discussed yet is the concern of introducing breaking changes to the master branch. I wasn’t explicit about it in the diagram above but I would normally not deploy from source when creating my pipelines. Instead, I use a package repo or, in the case of containerized services, a docker registry. Given this, even if a breaking change is introduced to the master branch, it will never propagate to the production registry since it will have been caught by any of the various stages of the pipeline.
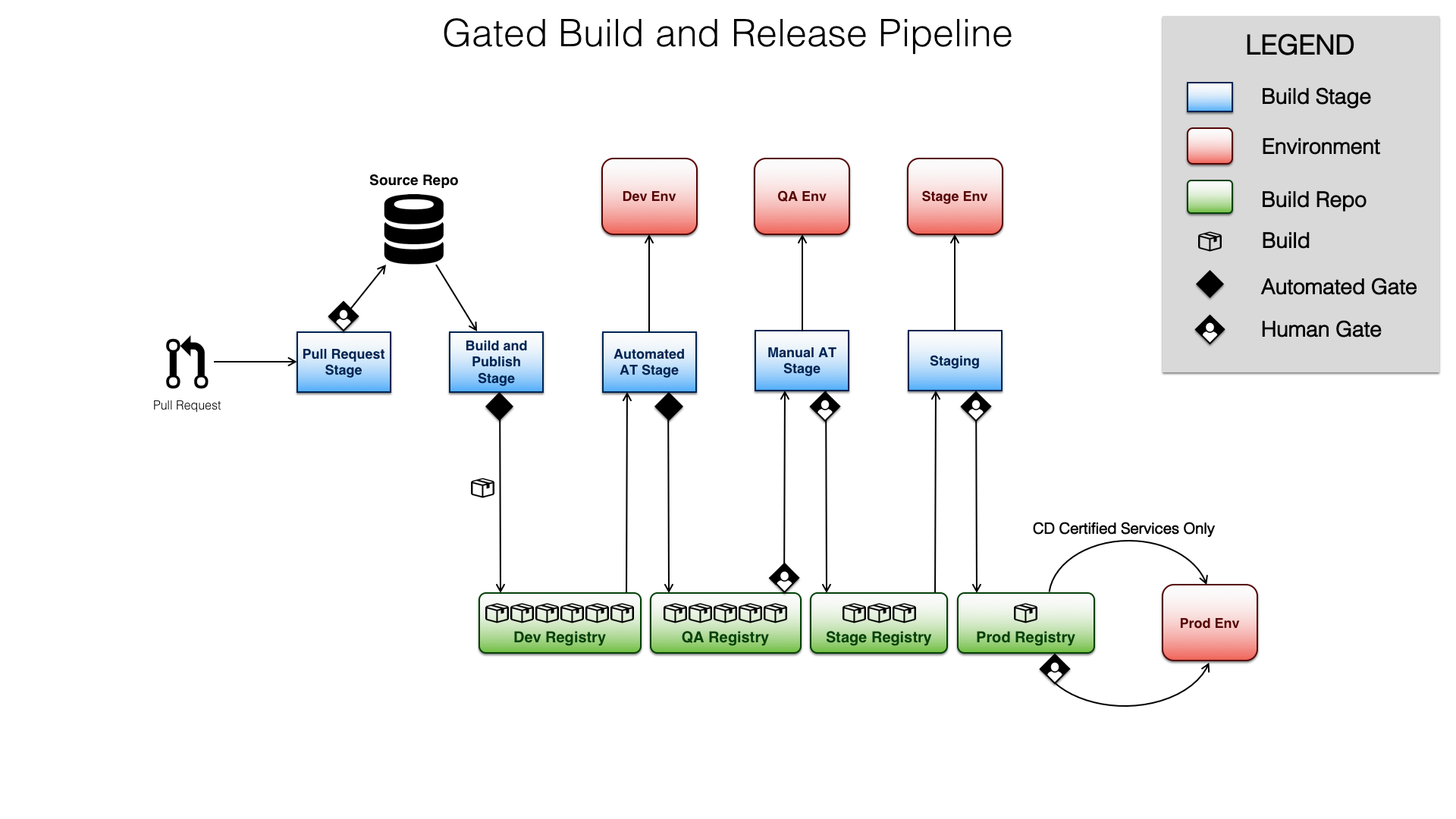
Here’s a sample pipeline diagram that I employ in some of my projects. Notice how the number of builds in the various registries (green boxes) decreases as you move to the right. That’s because the stages serve as the filters that work to keep broken builds from getting to production.
Demo Time!
Here’s a demo of the above strategy implemented in Jenkins.
The Groovy Code
Here are the basic parts to implementing a LIFO Queue in Jenkins. Make sure you’ve defined your stages the usual way. For example:
1
2
3
4
5
stage ('Automated Acceptance Tests'){
steps {
// Steps here
}
}
So far nothing is different from the usual stage definition. Now let’s add the part that turns this stage into a LIFO queue. First, you’ll need to make sure that you’ve installed the Lockable Resources Plugin. What this plugin does is it gives your pipeline the ability to create a cluster-wide “lock file.” Once you have that installed, modify your stage to look like the following:
1
2
3
4
5
6
7
stage ('Automated Acceptance Tests'){
steps {
lock(resource: "ProjectX-AAT") {
// Steps here
}
}
}
In line 3, we added a lock() call which is a global function that becomes available once you install the Lockable Resources Plugin. We then specify the name of the “lockfile” that we want to acquire, “ProjectX-AAT” in this case. Note that since the “lockfiles” created by Lockable Resources are global or cluster-wide, you have to add some “scope” in the lock name to avoid unnecessary contention with other projects that have nothing to do with yours.
Creating a lock in itself doesn’t produce a LIFO queue. By default, the lock
queue is implemented as a FIFO queue. To convert it to a LIFO queue, we add
the inversePrecedence option:
1
2
3
4
5
6
7
stage ('Automated Acceptance Tests'){
steps {
lock(resource: "ProjectX-AAT", inversePrecedence: true) {
// Steps here
}
}
}
By adding inversePrecedence: true to line 3, we are telling Lockable
Resource to grant the lock to the last build that requested it. Now we
have our LIFO queue!
We’re not quite done yet. While we’ve already implemented our LIFO queue for our Automated Acceptance Tests stage, we still aren’t able to cancel older builds in the queue. In fact, at this point, with the code that we’ve written thus far, once build 4 is done with the AAT stage, build 3 will proceed, then build 2. What we want is for build 2 and 3 to be cancelled as soon as build 4 is dequeued.
To achieve this, we will need another Jenkins plugin called Milestone. This is the plugin that allows newer builds to cancel old builds. Let’s put it to use:
1
2
3
4
5
6
7
8
stage ('Automated Acceptance Tests'){
steps {
lock(resource: "ProjectX-AAT", inversePrecedence: true) {
milestone 100
// Steps here
}
}
}
In lines 3 and 5 we inserted the milestone keyword with some arbitrary numeric value as an argument. What that line tell Jenkins is that if there are any older builds that haven’t passed this milestone, cancel them. Let’s do a walkthrough to clarify:
- On minute 1, Build 1 occuppies the AAT stage. It will run for 10 minutes.
- On minute 2, Build 2 enters the AAT stage and waits to acquire the lock for “ProjectX-AAT”
- On minute 5, Build 3 enters the AAT stage. It also waits to acquire the lock for “ProjectX-AAT”
- On minute 8, Build 4 enters the AAT stage. It waits to acquire the lock for “ProjectX-AAT”
- Build 1 is done with the AAT stage and moves one
- The lock for “ProjectX-AAT” is given to Build 4 since it was the last to request it. The milestone 100 line cancels Builds 2 and 3 since they have not passed that milestone yet.
Voila! Nothin’ To It.
So there we go. By just using two simple constructs from Jenkins, we are able to implement LIFO queues in any of our pipeline’s stages and, therefore, ensure that our Continuous Integration pipeline performs as intended.
Want to know about more strategies to ensure a healthy CI/CD pipeline? Go ahead and check out the Continuous Delivery book: